


前言:
好的选题何处寻?如何进行文献综述?如何实施研究?数据处理有什么要点?论文写作如何下手?为增进学术氛围,提高研究生学术兴趣,拓宽学术视野,让更多的学生懂研究,能研究,做好研究,写好学术论文,党委研究生工作部策划“研学有术”——学术科研经验分享系列推送,邀请在学术研究方面经验丰富的博士研究生撰稿,分享宝贵的学术论文写作经验,助力大家的科研学术之路。
本期“研学有术”邀请到统计学院经济统计系2020级博士研究生王祎帆为大家分享学术研究数据的获取、清洗、分析与解读。
撰稿人介绍:

王祎帆,统计学院经济统计系2020级博士研究生,师从杨翰方教授,研究方向为宏观经济与统计模型。相关研究曾发表于Energy Policy,Environmental and Ecological Statistics,《统计研究》《国际金融研究》《经济学家》《数量经济技术经济研究》等国内外核心期刊,并作为主要译者翻译《R数据可视化手册(第二版)》。主持中国人民大学研究生科学研究基金项目以及“交叉创新研究计划”项目。曾连续3年获得博士生学业一等奖学金、三好学生等荣誉奖励。
正文:
数据就像一个盒子,能够从里面获得什么取决于观察的角度、方式以及深度。数据有时候也可能是潘多拉魔盒,因为你永远不知道里面到底藏着什么,它会随着使用者的不同而产生不同的价值。作为科研工作者,我们首先要学会认识数据、理解数据,但更加重要的是合理地分析数据、客观地解读数据。
(一)数据的获取
在谈分析数据之前,我们首先要获取数据,这也是认识数据、理解数据的重要方式。获取数据的方式有两种,一种是亲自去进行田野调查,收集数据;一种是从现有数据库中下载。对于大多数人的研究,现有数据库里的数据已经十分充足了。由于数据库种类繁多,各个专业常用的数据库也有不同,这里我就介绍一个人大自己的数据库,也就是“中国人民大学中国调查与数据中心”提供的数据库,其本身可以满足很多社科研究的需求。但不管用什么数据,在获取数据的时候,一定要详细阅读数据的说明,包括但不限于数据的收集方式、数据含义、数据缺失情况等等。在确认数据符合自己研究的需求后再进行后续分析工作。

(二)数据的清洗
我们拿到的数据往往还需要再次加工,即进行“清洗”。数据的清洗工作本身其实不难,用R、Stata甚至Excel就可以完成,难点在于如何发现需要清洗的部分。研究中比较常见的部分有:
1. 数据缺失:需要对数据进行删减或者插值;
2. 数据异常:例如有的数据值明显不同于其他数据,且含义明显有误。我们首先需要用画图等方式去识别这些数据,然后进行后续的删减等操作;
3. 数据重复:有的时候数据集中会有重复的数据,并且理论上不应该重复,这也需要我们识别并删减;
4. 数据格式不一致:例如同样是日期变量,有的数据是“2023年1月1日”,有的则是“2023-1-1”,那么在数据分析之前需要将这些数据格式统一化。
其实在数据清洗过程中需要注意的地方还有很多,我这里介绍一个我个人比较常用的方式:画图。这里的画图没有那么复杂,往往一个折线图就能解决,但可以很清晰地看到数据的缺失情况、数据异常值以及很多其他问题。每一份数据都有着不同的特点,我们大可不必拿着一份“清洗清单”去一一核对,而是应该去“play with data”,去用各种描述统计(画图、求各种统计量)的方式来从各个角度观察数据,从而发现有待清洗的部分。
(三)数据的分析
清洗完数据后就需要对数据进行分析,一般人常用的分析方式可以分为两类:画图以及建模。画图的方式更加直观,而建模的方式可以剖析数据的内在情况。作为需要写论文的同学,对模型势必都有一定的了解,但往往在论文中都会“困于模型”。事实上,在数据分析的时候,画图或者说可视化应该是第一步,并且是必不可少的一步。这可以让作者和读者对数据的大概情况有所了解,一幅好的可视化作品有的时候甚至是可以直接得出结论的。大道至简,毕竟人的大脑对图像的接受程度是高于数字的。例如下面这个图展示了地球进化的过程。
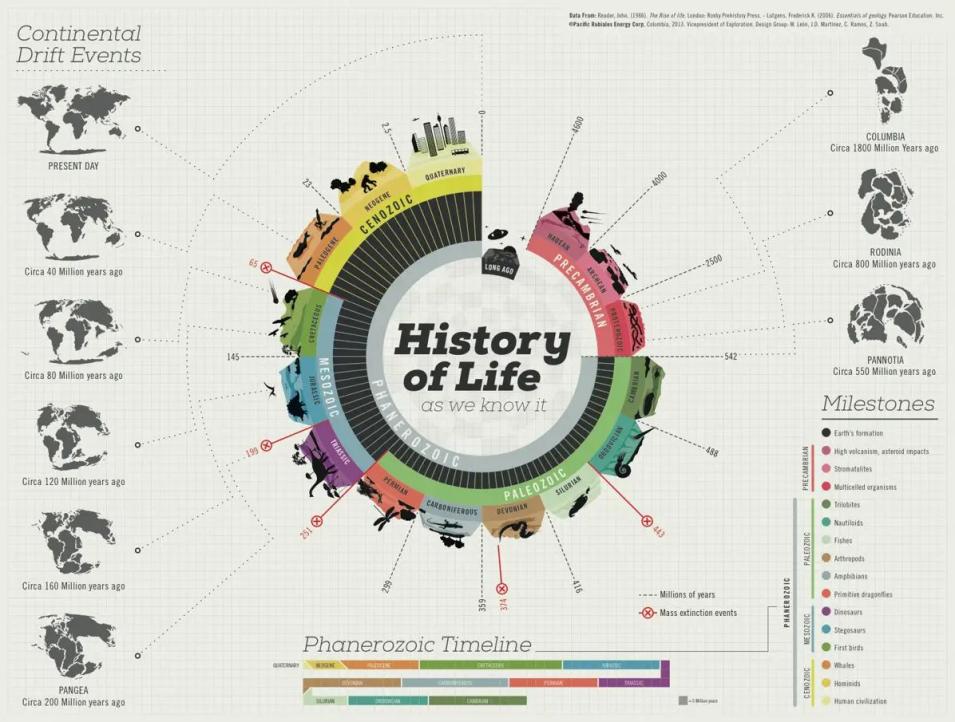
我们熟知的建模实际上是对画图的一个补充,或者说进一步验证可视化的结果。建模之后得到的结果也可以用可视化呈现,效果会更好。这里推荐一个B站的系列视频“【TED】统计学:可视化数据”,大家看完这个后或许对可视化会有更深入的理解。对于可视化感兴趣的同学,网上有很多可视化的网站,这里推荐Echarts,在R语言里也有相应的接口,可以画出很好看的交互式图形。
(四)数据的解读
数据分析之后就需要进行数据的解读,有人认为这一步最简单,因为这似乎只需要把数据分析的结果讲出来,例如A对B有显著正向的影响。但这一步实际上是最难的,一方面难在如何合理解读,为什么会有正向影响?会有什么影响机制?这些是论文区别于大作业的核心要素。我们需要在解读的时候对其背后的逻辑进行剖析,并适当地添加更多的可视化/模型结果。另一方面难在客观性,很多时候我们对数据结果有先入为主的观念,或者说“假设”,但往往有价值的发现源于数据分析结果与假设不符的地方,这时就需要我们客观地解读数据,从差异中寻找真理。
(五)潘多拉魔盒
最后,为什么说数据有时候是潘多拉魔盒呢?因为同样一份数据,在经过相同的数据分析过程后,可以通过不同的数据展现方式得到不同的结论。例如左图可以看到Revenue有明显上升,而右图也可以说Revenue比较平稳,然而两张图实际上只是更换了一下纵坐标的尺度。

这仅是潘多拉魔盒的冰山一角,数据的力量是无穷的,也是很容易迷惑人的,看似客观的数据可以融入很多主观的因素。数据可以用来帮助人类进步,也同样可以用来威胁人类,其价值取决于使用者的目的。我们应该了解其“魔力”,不被人所害,也更不要去危害他人。合理分析、客观解读,正确地使用数据,是我们每一个数据分析者的应有之义。
后记:对科研的感悟思考
(一)承认自己的平凡,努力奋斗
相信大部分选择读博士的同学,在最初都会对自己的学术水平或者智力水平有一定程度上的信心。但往往一开始对自己最有信心的那批人反而会面临延毕的风险,因为这些“信心”会刺激他们去挑战看似很近但实则遥不可及的高峰。事实上,在我身边,甚至包括我常听讲座的那些“大佬”们,真正天才的少之又少,绝大多数还是普通人。我认为真正区分“大佬”和其他科研工作者的关键点在于努力。当然我们不能忽略运气以及选择的作用,但也只有努力是我们可以控制的。
(二)走出工位,走出图书馆
相比本科,研究生们在做科研时会长时间待在工位/图书馆中,但我们真正应该做的其实是走出来。一方面是要强健体魄,毕竟身体是革命的本钱;另一方面是要和各种各样的人交流,和同学、老师、业界的前辈们等等,这样可以从多角度加深对研究问题的理解,从而得到更合理、更具实际意义的解决方案。亦或者仅仅是找个人说说话,聊聊天,舒解一下科研压力,这对于情绪管理是相当有帮助的。
(三)做有趣的研究
研究可以分为两种,一种是有意义,另一种是有趣。这两种并不互斥,但如果非要选一个,我认为应该选有趣的研究。因为科研本身是枯燥的,需要不断的试错,此时兴趣就成为了坚持下去的最大动力,并且有趣的研究做扎实了也是可以发到很好的期刊上的。另外,即使当前看起来意义不大的研究,在未来的某个时间可能就是热点,甚至于是推动人类进步的重要研究之一。



